
Numérique et Soutenabilité 🇫🇷
Présentation des idées que je développe dans mon projet de recherche portant sur l’étude de la soutenabilité (ou non soutenabilité) de l’intelligence artificielle ubiquitaire.
Il propose un modèle s’inspirant de la littérature scientifique de la communauté “Social Ecology,” proposant un modèle d’étude calqué sur la vie d’un organisme biologique et le combinant avec les aspects sociaux-économiques. Dans le modèle proposé, je considère les aspects socio-techniques de l’IA sous forme de trois blocs interagissant: les flux, les infrastructures et les besoins. Je me propose, de détailler ce modèle en utilisant les outils communément utilisées par la communauté des Systèmes d’informations ainsi que d’autres approches dans un esprit de décloisonnement multi-disciplinaire. Les contributions prévues sont une modélisation du métabolisme de l’IA ubiquitaire dans la société contemporaine, l’étude de ces limites au travers du prisme d’une planète finie et des pistes de birfurcation du modèle dominant vers un modèle soutenable, si tant est qu’il puisse exister. Ce travail s’appuie sur mes précédentes recherches menées au CRI concernant les principes et techniques de décentralisation et d’auto-souveraineté rendue possible par la blockchain1, ainsi que mes axes de recherche actuels traitant de la confiance des systèmes d’information2 et les expérimentations sur IA embarquée légère en substitution des modèles centralisés. Il s’agit ici d’outiller une réflexion critique sur l’IA, ses promesses et ses limites, en croisant les apports des sciences du numérique avec ceux des approches systémiques et socio-écologiques.
Motivations pour le métabolisme social et application à l’IA
L’approche retenue s’appuie sur un vaste corpus de recherche issu du social metabolism, défini comme « Le métabolisme social englobe les flux biophysiques échangés entre les sociétés et leur environnement naturel, ainsi que les flux au sein des systèmes sociaux et entre eux. » [Haberl et al. 2019].
Cette démarche scientifique s’inspire des communautés du Urban Metabolism, de l’Ecological Economics, de l’Energy and Material Flow Analysis, ainsi que des approches type Life-Cycle Assessment ou Integrated Assessment Models.
Elle repose sur le triptyque (nexus) stock-flux-services3, représentant à l’origine le stock de matière, les flux de matières, et les services sociétaux rendus possibles par ces derniers.
L’un des apports majeurs du métabolisme social est la mise en évidence de plusieurs phénomènes systémiques :
- des phénomènes de verrouillage (lock-in ou legacies) entre ces trois composantes,
- de fuite (leakage), lorsque l’adoption d’un nouvel artefact entraîne une augmentation de la consommation d’un autre,
- et d’effet rebond, lorsque l’adoption d’un service supposément plus économe augmente en réalité son empreinte environnementale du fait de la croissance de son usage.
J’ai choisi d’appliquer ce cadre conceptuel à l’analyse de l’IA pour trois raisons :
- D’une part, la montée en puissance de cette technologie tend à rendre son usage pervasif dans la société, à tel point que de nombreuses nouvelles “opportunités” d’application de l’IA apparaissent dans tous les secteurs industriels et dans la plupart des foyers (au moins dans le Nord global), avec un risque de dépendance technologique croissante.
- D’autre part, ses fondements technologiques présentent une empreinte environnementale très importante4.
- Enfin, le déploiement massif des data centers nécessaires à l’infrastructure de l’IA a un fort impact territorial et soulève de nombreux enjeux de compétition pour les ressources [Lopez and Diguet 2023].
Même si de nombreuses recherches considèrent l’IA comme bénéfique dans certains domaines — notamment pour la réduction des GES [SaberiKamarposhti et al. 2024] [Adegbite et al. 2024] — les études portant sur les effets systémiques de l’IA restent rares et circonscrits aux (néanmoins importantes) considérations sur l’éthique de l’IA [Stahl et al. 2023].
je cherche à mieux comprendre les impacts systémiques du déploiement de l’IA, d’étudier la soutenabilité du modèle d’IA ubiquitaire, et de proposer des pistes de bifurcation vers des alternatives soutenables.
Dans ce document, je débute par donner un exemple illustratif d’une étude métabolique simpliste portant sur une infrastructure de transport (Section ). L’objectif de cet exemple et guider le lecteur dans la compréhension du modèle FIB (Section ). je poursuis en expliquant comment le modèle utilisé peut nous permettre de raisonner sur la stabilité d’un système (Section ) en tenant compte de ses caractéristiques et des effets de 1, 2 et 3e ordre. je continue en appliquant le modèle à l’étude du métabolisme de l’IA (Sections , , ) et justifie la nouveauté de cette approche. Finalement, je propose des pistes de mes prochaines recherches dans ce cadre théorique (Section ).
Exemple illustratif d’une étude socio-métabolique
je commence cette présentation en décrivant un modèle métabolique simpliste, à visée purement illustrative, concernant l’évolution des transports en commun de la ville de Bordeaux au XXe siècle.
Contexte
En 1900 le maire de Bordeaux M. Cousteau inaugure la première rame du tramway électrique de Bordeaux, supplantant les anciens modèles à traction hippomobile. A son apogée en 1946 celui-ci atteindra un réseau de 253km, 40 lignes pour un total de 160.000.000 de voyageurs par an (soit 400 voyageurs par an par habitant). M. Chaban-Delmas, maire entre 1947 et 1995, décide dès 1948 de supprimer totalement le réseau du tram pour remplacer par un parc d’ autobus. Une des raisons de ce choix est la contrainte que posent les tracés en site propre du tramway sur la circulation automobile individuelle. En 1997, devant l’asphyxie routière de la ville et l’échec du projet de métro, M. Jupé, maire nouvellement élu décide, avec la communauté urbaine de bordeaux, de relancer un projet de création de trams dont les travaux dureront 3 ans pour la livraison initiale et atteindra 68.000.000 de voyageurs par an en 2023 (soit 83 voyageurs par an par habitant)5.
A noter que l’exemple de Bordeaux n’est pas un phénomène isolé, mais un des très nombreux exemples [Turnheim 2023].
Modèle FIB appliqué au démantèlement du tram à Bordeaux.
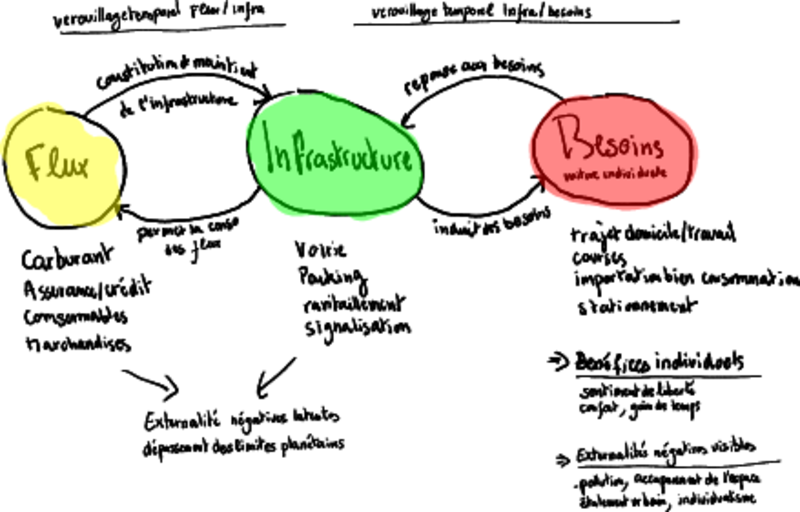
La Figure montre l’interaction entre les 3 composants de notre modèle, les flux, l’infrastructures et les besoins.
- Les “Flux”6 sont les composants matériels ou immatériels qui rentrent et sortent de notre système avec une durée de vie brève (arbitrairement prise < 1 an) et qui sont mesurés sur une période donnée.
- Les infrastructures7 sont les composants matériels ou immatériels avec une durée de vie plus longue, qui restent un certain temps dans le système.
- Les besoins8 sont ce qui pousse les individus à agir dans notre système, au travers des moyens mis à leur disposition par l’infrastructure sous la forme de need satisfier d’après [Max-Neef et al. 1991].
En premier ordre, les flux sont utilisés pour construire les infrastructures, et les infrastructures créent pour répondre aux besoins.
Il y a également d’autres relations entre les composants du modèle, de deuxième ordre: l’infrastructure n’est pas neutre vis-à-vis des flux ni des besoins. Le déploiement de l’infrastructure appelle une augmentation du flux9 nécessaire pour la maintenir. L’augmentation de l’infrastructure disponible appelle également à la mise à disposition de nouveaux moyens pour satifsaire les besoins10.
D’autres effets de troisième ordre apparaissent également. Les bénéfices individuels sont tempérés par des externalités négatives. Dans notre exemple: non seulement l’augmentation du besoin de déplacement en voiture individuelle va augmenter les émissions polluantes, mais également reconfigurer l’espace urbain en rendant possible le développement périurbanisation ainsi que les zones commerciales à grande échelle en périphérie, atteignables principalement en voiture. À noter que l’augmentation de la quantité d’infrastructure et de flux se heurte au dépassement des limites planétaires, rendant le système non soutenable à terme.
La difficulté de la situation est le verrouillage entre d’une part les flux et les infrastructures et d’autre part entre les infrastructures et les besoins:
- La construction d’une infrastructure est d’une forte intensité capitalistique et appelle à une rentabilisation des investissements sur le temps long. Dans ce cadre, il est difficile de revenir sur les décisions de constitutions de l’infrastructure et la tendance est d’attendre la rentabilisation complète avant de procéder au démantèlement11.
- D’autre part, l’adaptation progressive des moyens de réalisation des besoins par les infrastructures crée une forme de dépendance. Cette dépendance rend plus difficile l’acceptation de toute modification profonde de ces infrastructures.12.
Le verrouillage contribue à la stabilité du système, créant des forces rendent difficile un changement de paradigme (réforme des flux, infrastructure et besoin). Cette stabilité peut être perçue comme dommageable, lorsqu’elle est confrontée aux effets négatifs de troisième ordre (externalités négatives, dépassement des limites planétaire)13.
Il peut être tentant de se demander si une lecture systémique du métabolisme urbain aurait permis d’anticiper les effets de long terme liés au démantèlement de certaines infrastructures. Toutefois, une telle hypothèse doit être maniée avec prudence. Les choix d’aménagement urbain — comme ceux qui ont conduit à la suppression puis à la reconstruction du tramway bordelais — ne relèvent pas uniquement de logiques d’optimisation fonctionnelle. Ils sont aussi le produit de contextes historiques spécifiques, de rapports de force politiques, d’intérêts économiques sectoriels, et de représentations dominantes du progrès à un moment donné.14 La saturation actuelle des systèmes de transport ne peut donc être comprise qu’à travers cette complexité, dans laquelle les flux ne sont qu’un des éléments du système.
Formalisation du modèle FIB

Pour décrire précisément le modèle FIB, j’ai adopté une approche fondée sur les travaux de Guizzardi [Guizzardi 2005], en m’appuyant notamment sur l’ontologie fondationnelle UFO (Unified Foundational Ontology). Ce cadre ontologique offre une modélisation rigoureuse des entités, de leurs relations, et des dépendances ontologiques entre celles-ci. Il permet de représenter de manière explicite, à l’aide d’un diagramme de classes15, les concepts structurels et dynamiques sous-jacents au modèle FIB, tout en assurant la cohérence sémantique de l’ensemble.
Les trois principaux composants du système (Flows, Infrastructure et Needs) sont représentés. Il existe deux types de relations entre ces composants : les relations de premier ordre (Infrastructure Building et Primary Infrastructure User) et les relations de second ordre (Infrastructure Maintenance et Induced Infrastructure Use). Les Flows ont été séparés en deux pour indiquer leur contribution respective aux relations de premier et de second ordre. De la même façon, les Induced Needs, qui sont les coproduits de l’utilisation primaire de l’infrastructure, sont la conséquence de la relation de premier ordre entre les Needs et l’Infrastructure, et la cause de la relation de second ordre entre ces deux composants.
Les besoins n’étant pas des acteurs agissants, je fais apparaître l’entité Users, représentant l’utilisateur de l’infrastructure. Dans ce modèle, l’entité User aspire au bien-être (well-being), qui peut être décliné en deux formes distinctes : le bien-être hédonique16 et le bien-être eudémonique17 [Lamb and Steinberger 2017]. Je choisis de considérer que les besoins suscitant la création d’infrastructures sont pilotés par la recherche de bien-être hédonique.
Les Flows et Infrastructures sont des agents exerçant un impact systémique direct, contrairement à l’utilisateur, qui a un impact indirect au travers de l’utilisation de l’infrastructure. Ces impacts produisent des effets de troisième ordre sous forme d’externalités. Les externalités peuvent être perçues, lorsque la relation causale entre l’entité impactante et l’effet est directement perceptible par l’utilisateur, ou latentes dans le cas contraire18.
Les externalités négatives perçues ont un impact sur le bien-être hédonique, dans le sens où elle. Les externalités latentes, en revanche, impactent négativement le bien-être à travers sa composante eudémonique19.
Dans le cadre de l’application de ce modèle selon une approche par systèmes complexes, il est d’ores et déjà pertinent d’identifier les boucles de rétroaction qui entrent en jeu dans la stabilité du système :
- La boucle Flows–Infrastructure est auto-entretenue en raison de la nécessité de maintenir l’Infrastructure existante.
- La boucle Infrastructure–Needs est également auto-entretenue, mais modulée par la diminution des besoins liée aux externalités négatives perçues.
- Les externalités négatives latentes n’interviennent qu’au travers de leur impact sur le bien-être eudémonique. Elles n’exercent donc pas d’effet modérateur direct sur les besoins. Une réduction drastique du bien-être eudémonique pourrait entraîner une dégradation du bien-être global, susceptible d’être compensée par une intensification de la recherche de bénéfices individuels. Inversement, les motivations hédoniques à l’origine des besoins peuvent être affaiblies en l’absence de quête explicite de bien-être hédonique.
- Enfin, les externalités négatives latentes sont un facteur limitant des entités impactantes. En d’autre terme, celles-ci peuvent se voir limiter si elles dépassent un certain seuil de soutenabilité.
L’analyse intuitive de ce système nous permet de mettre à jours 3 états stables obtenus au travers de 3 scenarios20:
- scénario décroissance: supression de la recherche de bien-être hédonique, qui a comme effet de 1er ordre la limitation des infrastructures et comme effet de 2e ordre, celui des flux.
- scénario effondrement: l’effondrement des infrastructures et des flux liés au dépassement des limites pour les externalités négatives latentes. Ce cas de figure entraine une limitation forcée des besoins, ceux-ci ne pouvant pas être satisfaits en raison de l’absence d’infrastructure.
- scénario atterrissage contrôlé, prise de conscience et limitation: une limitation des flux et Infrastructure, jusqu’à atteindre un niveau d’externalité négative latente n’impactant pas suffisamment la recherche de bien être eudémonique pour susciter une limitation naturelle de la recherche de bien être hédonique, qui limiterait les besoins. L’existence d’un état stable dans ce dernier scénario n’est pas garantie, car elle dépend des lois physiques, de l’état initial du système et de la capacité des parties prenantes à prendre conscience et accepter une limitation d’usage qui refléterait la réalité physique d’une limitate des ressources.
Après avoir détaillé le modèle, Je propose ici d’exposer mon projet de l’appliquer au métabolisme de l’IA.
Application du modèle FIB pour l’étude du métabolisme de l’IA
Nous allons à présent analyser le métabolisme de l’IA à l’aide du modèle FIB présenté précédemment. Notre objectif est triple :
D’une part, je spécialiser le modèle FIB présenté Figure en y intégrant les éléments spécifiques à l’IA. Notons que les éléments proposés constituent une première approche naïve, et que le développement de ces modèles est appelé à être affiné dans des travaux futurs. Puis, j’analyse les dynamiques émergentes propres à l’IA au sein du modèle spécialisé, afin de mieux comprendre ses propriétés de stabilité. Enfin, je proposer des idées de contributions scientifiques à court et moyen terme visant à enrichir le modèle et proposer des solutions.
Les Flux

Dans ce document, nous simplifions le problème en ne considérant que les flux entrants, en ignorant les exutoires21 ainsi que les flux de transport des matières. D’autres flux entrants sont également ignorés pour nous concentrer sur deux grandes catégories: les flux matériels et les flux informationnels.
Les flux matériels proviennent des opérations de construction et de maintenance du matériel informatique nécessaire à l’exécution des tâches du cycle de vie de l’IA22. Dans le cas d’une IA centralisée (e.g., ChatGPT) et/ou mutualisée (e.g., Amazon Bedrock, AWS), la majeure partie des flux de construction d’infrastructure se concentrent dans les centres de données. De nombreux flux de matériaux sont nécessaires, comme les minerais métalliques ou les terres rares. Ces ressources sont non renouvelables à l’échelle de temps humaine, ce qui conduit à une raréfaction progressive. Selon le type de ressource et sa concentration dans l’environnement, cette raréfaction peut engendrer des effets négatifs différés : toute extraction non renouvelable se fait au détriment des besoins futurs. À titre d’exemple, aujourd’hui, le consommateur ne perçoit pas directement l’impact à long terme de la diminution du stock de cuivre. Selon l’élasticité des prix de la matière première, il pourra en percevoir l’externalité négative par une hausse des prix, sans que cela soit systématique.
D’autres flux sont potentiellement renouvelables. Les flux d’électricité ou de refroidissement peuvent l’être au premier ordre sous certaines conditions imposées à l’infrastructure de production, par exemple via l’usage d’hydroélectricité ou d’énergie éolienne23. Cette hypothèse ne tient toutefois plus au second ordre : les moyens de production de ces flux dépendent eux-mêmes d’infrastructures construites avec des flux non ou partiellement renouvelables24. Même en ignorant les effets de second ordre, un phénomène de compétition d’usage se manifeste : l’installation de centres de données limite l’accès à l’électricité pour les infrastructures voisines [Lopez and Diguet 2023], entrainant donc des externalités négatives.
Les flux de données sont essentiels à toutes les étapes du cycle de vie de l’IA : lors de la création des modèles, de leur utilisation, et pour leur maintenance en cas de model drift25, afin de préserver leur performance par réentraînement.
Les données utilisées peuvent être publiques ou privées. Les flux de données publiques ne présentent pas d’effets négatifs particuliers au premier ordre. Néanmoins, la performance visée par les modèles se heurte à deux limites :
- les données personnalisées sont les plus utiles aux utilisateurs, mais nécessitent l’usage de données privées ;
- l’augmentation des flux de données publiques peut être nécessaire pour améliorer les performances des modèles.
Dans un cas comme dans l’autre, l’usage des données privées s’avère nécessaire. L’utilisateur devra fournir ses données personnelles s’il souhaite une meilleure performance du modèle (e.g. c’est le cas des assistants personnels ou des moteurs de recommandation). Il pourra même y être contraint par la puissance publique26 ou incité par des acteurs privés en échange d’un accès à leurs services27. Le législateur prévoit néanmoins de renforcer la prise de conscience des utilisateurs quant à l’usage de leurs données, notamment à travers les textes encadrant la protection des données personnelles (p. ex. RGPD), qui imposent de recueillir leur consentement avant toute captation. Cette dernière observation nous permet de classer que l’utilisation des données privées comme une externalité négative.
Les infrastructures

Les infrastructures mobilisées par l’IA héritent en grande partie de celles déjà mises en œuvre pour d’autres usages :
- Ressources humaines : il s’agit des personnes formées à l’utilisation des outils d’IA, ainsi que des professionnels spécialisés dans leur conception et leur maintenance. Le cas des utilisateurs est particulier, car de nombreuses solutions d’IA reposent sur l’apprentissage par renforcement à partir de feedback humain (RLHF), où l’usage même des outils permet d’exprimer une préférence sur les résultats produits. Ces retours sont utilisés pour améliorer les modèles. Cela instaure une dynamique de rendements d’échelle croissants : plus les systèmes sont utilisés, plus ils deviennent performants pour l’ensemble des utilisateurs. D’autres ressources humaines sont dédiées à l’amélioration des solutions : les data workers28 participent à la création et à la qualité des datasets, tandis que les AI engineers travaillent à l’optimisation des modèles. Ces derniers sont hautement qualifiés, nécessitant plusieurs années de formation universitaire, ce qui impact leur disponibilité sur le marché du travail et la création de formations spécifiques.
Infrastructure informationnelle : elle comprend principalement les datasets utilisés pour l’entraînement, les modèles utilisés pour l’inférence, et un éventuel composant d’apprentissage (learning). Les autres composants logiciels sont proches de ceux des systèmes informatiques traditionnels et sont ignorés en première approximation. Tous ces éléments reposent sur des ressources physiques. Si les datasets peuvent être stockés avec des technologies big data standardisées, les composants d’apprentissage et les modèles exigent des ressources matérielles spécifiques (GPU, TPU, NPU, mémoire rapide), souvent peu réutilisables hors du contexte IA.
Infrastructures physiques : elles incluent les data centers, qui réalisent aujourd’hui l’essentiel des opérations d’apprentissage à grande échelle, les infrastructures énergétiques nécessaires à leur fonctionnement, ainsi que les dispositifs d’interaction avec l’IA (mediation layer). La couche data entry points regroupe les dispositifs physiques servant à capter des données pour alimenter les datasets. Il peut s’agir de périphériques grand public (personal devices) comme les PC ou smartphones, ou de dispositifs dédiés tels que des capteurs IoT ou des équipements médicaux. Les interface devices (dispositifs d’interface) désignent les dispositifs par lesquels les utilisateurs interagissent avec les systèmes d’IA. Ils incluent à la fois des périphériques classiques (PC, smartphones) et des dispositifs spécialisés dotés de capacités d’inférence ou d’apprentissage local, comme les casques de réalité virtuelle ou les edge devices. Une partie du cycle de vie de l’IA peut ainsi être déportée en périphérie du réseau afin d’améliorer les performances en termes de latence. Le nombre de dispositifs intégrant des capacités IA est en constante augmentation, avec des interfaces de plus en plus spécifiques à certains usages.
Régulation : l’IA est encadrée par des réglementations spécifiques29 portant sur l’ensemble du cycle de vie des systèmes, ainsi que par des réglementations plus générales (privacy regulation, environmental regulation) ayant un impact sur certaines de ses composantes.
- Les privacy regulations régulent l’utilisation des données personnelles30.
- Les régulations environnementales imposent des contraintes sur l’empreinte écologique des infrastructures physiques. Cela inclut par exemple les règles sur l’artificialisation des sols par les data centers (ex. “zéro artificialisation nette”), ou celles limitant les émissions de CO231.
- Certaines de ces règles sont juridiquement contraignantes (binding regulations), d’autres relèvent de principes directeurs non contraignants (guiding principles).
Le sous-système infrastructurel de l’IA peut être vu, en première approximation, comme un système autorégulé : certains composants consomment des ressources (infrastructure physique), tandis que d’autres sont conçus pour encadrer cette consommation et garantir la conformité aux valeurs de la société d’accueil (infrastructure de régulation)32. Le système est également auto-améliorant, dans le sens où les utilisateurs participent à l’amélioration continue des modèles. À demande constante, il peut ainsi devenir de plus en plus efficient.
Cependant, comme nous l’avons vu, la dynamique de l’infrastructure dépend des besoins humains, tout en en générant de nouveaux. Sa stabilité doit donc être analysée de manière systémique : les effets de second ordre contribuent à la croissance continue des besoins infrastructurels appelée par l’amélioration des systèmes. De plus les modèles étant sujet à un model drift (dérive du modèle), celui-ci doit être entretenu par l’ajout continu de nouvelles données aux datasets. Une grande partie de la littérature se concentre sur l’amélioration des performances environnementales de l’IA, ce qui constitue bien entendu un progrès pour le domaine [Verdecchia et al. 2023]. Néanmoins, ces considérations ne suffisent plus lorsque l’on s’intéresse au métabolisme pour adresser les challenges d’un point de vue systémique. D’autres chercheurs vont plus loin en prenant en considération les impacts directs [Morand et al. 2024] et indirects [Wilson et al. 2024] des infrastructures, et donnent des résultats très dépendants du contexte et illustrant (1) la difficulté à mettre en évidence les phénomènes et (2) les challenges méthodologiques inhérents.
Les besoins
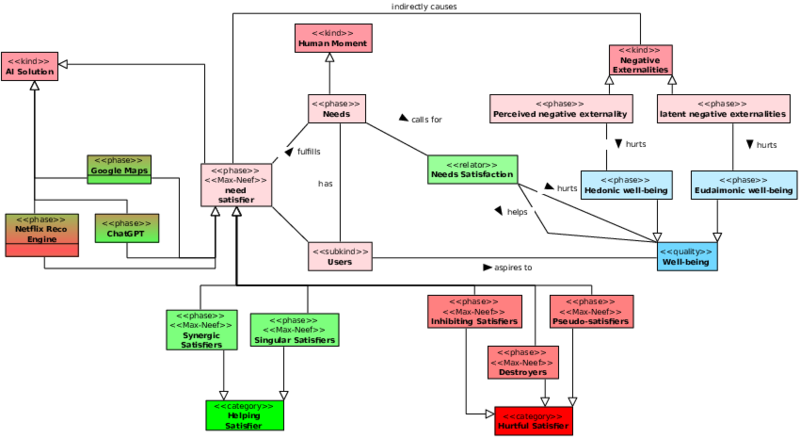
Les êtres humains ont des besoins, au sens de [Max-Neef et al. 1991]. Ces besoins sont satisfaits à l’aide de Need Satisfiers, que l’on peut regrouper en deux grandes catégories : les Helping Satisfiers et les Hurtful Satisfiers.
On distingue plusieurs types de Satisfiers :
- Synergic Satisfiers : ils répondent efficacement au besoin visé, tout en contribuant simultanément à la satisfaction d’autres besoins.
- Singular Satisfiers : ils satisfont un besoin spécifique, sans influencer notablement les autres.
- Inhibiting Satisfiers : ils répondent à un besoin, mais nuisent à la satisfaction d’autres besoins.
- Destroyers : ils prétendent répondre à un besoin, mais empêchent en réalité sa satisfaction, ainsi que celle d’autres besoins.
- Pseudo-Satisfiers : ils procurent une satisfaction apparente à court terme, mais compromettent la satisfaction du besoin à moyen ou long terme. Ce sont une forme particulière de Destroyers, dont les effets négatifs sont mal perçus au moment de leur mise en œuvre.
Ces Satisfiers peuvent générer des externalités négatives qui affectent le bien-être, tout en constituant, paradoxalement, les conditions mêmes de possibilité de ce bien-être. Certains usages de l’IA peuvent être aisément classifiés. Par exemple, la génération de deepfakes à des fins trompeuses ou les cyberattaques ciblant les systèmes de santé relèvent clairement des Destroyers. On remarque que le Human Moment (l’intention) est primordial dans cette classification, car il permet de distinguer les usages intentionnellement malveillants. D’autres usages de l’IA ne suscitent pas de débat : la solution AlphaFold, qui permet la prédiction de la structure des protéines, ou encore l’utilisation de l’IA pour la détection précoce de pathologies, représente des avancées scientifiques majeures en biologie. De même, l’analyse automatisée des données sismiques pour la prévision des séismes constitue une contribution directe à la sécurité des populations. Enfin, certains usages sont plus ambivalents. L’utilisation de ChatGPT par les étudiants peut les aider à reformuler les concepts abordés en cours, mais elle facilite également la triche lors des remises de projets, ce qui compromet l’acquisition des compétences visées par un diplôme. Le système de recommandation de Netflix propose du contenu personnalisé, mais peut également réduire la diversité culturelle dans la consommation des médias33. Les Helping Satisfiers contribuent au bien-être eudémonique, tandis que les Hurtful Satisfiers peuvent améliorer temporairement le bien-être hédonique. Toutefois, chacun de ces Satisfiers est susceptible de générer des externalités négatives latentes et n’est pas intrinsèquement soutenable. Il est également important de noter que de nombreux articles font référence à l’IA comme une solution possible aux problèmes environnementaux, même si la question ne doit pas être uniquement traitée sous l’angle des besoins [Schoormann et al. 2023]
Le sous-système des besoins permet ainsi d’opérer un premier classement quant à la soutenabilité des solutions d’IA, rapportée aux intentions des utilisateurs, selon une analyse de premier ordre. Néanmoins, la soutenabilité systémique requiert également la prise en compte des effets de second et de troisième ordre pour évaluer pleinement l’opportunité du déploiement de ces solutions.
Travaux futurs
Cette section présente les travaux en cours et à venir, qui visent à contribuer au champ de recherche de l’étude du métabolisme de l’IA, en positionnant mes recherches dans le cadre du modèle FIB décrit précédemment. Celui-ci ouvre la voie à de nombreuses contributions scientifiques, découpées en 4 axes: d’une part, un axe méthodologique permettant d’affiner le modèle, puis des axes ciblant spécifiquement chacun des sous-systèmes du FIB.
Axe méthodologique: Raffinement du modèle FIB
Comme mentionné plus haut, de nombreux facteurs ont été laissés de côté dans notre modélisation initiale. Une analyse plus complète du cycle de vie, se basant sur les travaux existants [Bouza et al. 2023] et un approche systémique [Ekchajzer et al. 2024] permettrait d’approfondir la compréhension de la soutenabilité réelle du système. La difficulté, au-delà de l’obtention des données, est la prise en compte des effets de 2e et 3e ordre (effets rebonds) représente un véritable défi pour les chercheurs et les autorités publiques[Courboulay 2023].
Il serait également pertinent d’interroger les causes de la transformation actuelle vers une société de plus en plus dépendante de l’IA. La seule disponibilité des capacités techniques issues de l’innovation ne suffit pas à expliquer un tel basculement. Cette dynamique semble plutôt s’inscrire dans des transformations sociétales plus profondes — économiques, culturelles et politiques — qui reconfigurent les représentations du progrès, de l’efficacité et du bien-être34.
Axe Besoins: Adoption de l’IA - le double jeu de la confiance
La confiance, entendue comme « la volonté d’une partie de se rendre vulnérable aux actions d’une autre partie » [Mayer et al. 1995], joue un rôle central dans l’adoption des solutions d’intelligence artificielle.
Cependant, l’étude de la confiance appliquée aux systèmes techniques s’adapte difficilement aux systèmes fondés sur l’IA. Si certaines dimensions classiques demeurent pertinentes — telles que la performance ou la transparence —, les caractéristiques anthropomorphiques des systèmes d’IA tendent à brouiller les repères traditionnels de l’analyse de la confiance [Lankton et al. 2015].
Partant de ce constat, nous avons entrepris un travail sur les mécanismes de confiance dans les systèmes d’IA, non dans une optique de promotion ou de renforcement de la confiance des utilisateurs, mais afin d’identifier les facteurs qui la génèrent, leurs interactions, et les conditions d’émergence d’une confiance légitime35.
Cette distinction est essentielle dans le cadre de la classification des besoins. En effet, Max-Neef identifie les Pseudo-Satisfiers comme des solutions imposées à l’individu par la propagande ou la publicité, qui empêchent à terme la satisfaction authentique de ses besoins. Replacer la confiance dans l’IA à sa juste place permet ainsi de mieux qualifier les usages légitimes au service des besoins humains, indépendamment de la question de leur soutenabilité matérielle.
Axe Infrastructure et Flux: faisabilité et évalution des solutions d’IA décentralisées
Comme illustré par l’application du modèle FIB, le déploiement du modèle centralisé de l’IA que nous connaissons actuellement pose des problèmes en termes de flux et d’infrastructures. Nous avons également commencé à étudier la substituabilité de ce modèle dans le cas des assistants domotiques36. Ceux-ci — tout comme, à plus grande échelle, le concept de smart building — montrent, en première approche, des gains d’efficacité énergétique et une réduction des coûts de maintenance [Ejidike and Mewomo 2023], à nuancer par l’impact environemental du déploiement massif de ces solutions.
Nous explorons la possibilité qu’ un modèle déconnecté, explicable et coachable pourrait répondre aux défis posés par la non-soutenabilité des flux, le respect de la vie privée et les limitations des infrastructures actuelles.
Nous développons actuellement un prototype d’edge device37 pour répondre à ces enjeux tout en maintenant un haut niveau de service et une acceptation par les utilisateurs [Vrain and Wilson 2024].
La décentralisation passe également par l’adoption de solutions permettant une réappropriation des données de l’utilisateur, n’excluant pas les usages tiers s’ils sont jugés nécessaires. L’étude de solutions blockchains mise en œuvre dans le cadre de l’identité auto-souveraine [Preukschat and Reed 2021] est une piste qui permettraient un contrôle fin de ces données et de leur usage dans les systèmes IA, encore une fois après une étude de la soutenabilité.
Axes limites: Dépassement des limites planétaires et cognitives
Si les rapports du GIEC ne laissent plus de doute sur le dépassement des limites planétaires, une autre menace liée au déploiement des solutions d’IA réside dans le dépassement des limites cognitives humaines. En effet, c’est la performance, et non l’explicabilité, qui constitue aujourd’hui l’objectif principal des promoteurs de ces technologies.
La crainte est celle d’un développement tel que l’humain ne soit plus en mesure de comprendre ou d’interpréter les résultats produits par des modèles devenus indispensables au fonctionnement de nos sociétés.
Il apparaît donc essentiel d’étudier plus en détail les limites cognitives humaines à respecter, ainsi que les moyens techniques permettant de garantir leur prise en compte par les systèmes d’IA.
Conclusion
Ce document pose les bases conceptuelles et méthodologiques de mes travaux futurs portant sur le métabolisme de l’intelligence artificielle, en m’appuyant sur une approche fondationnelle formalisée via le modèle FIB. En articulant les flux, les infrastructures et les besoins, ce cadre permet d’analyser la stabilité et la soutenabilité des systèmes sociotechniques intégrant de l’IA.
L’application de ce modèle à l’IA ubiquitaire révèle des dynamiques complexes, où les gains apparents en performance ou en confort s’accompagnent souvent d’externalités négatives, de verrouillages structurels et d’effets rebonds systémiques. La prise en compte des dimensions humaines, réglementaires et matérielles, ainsi que des effets de second et de troisième ordre, apparaît essentielle pour comprendre les trajectoires actuelles et envisager des bifurcations soutenables.
Les axes de recherche proposés ouvrent la voie à des contributions interdisciplinaires, visant à explorer des alternatives technologiques et organisationnelles — notamment par la décentralisation, l’explicabilité, et la redéfinition des usages légitimes de l’IA au regard des besoins humains. Le travail amorcé ici constitue une première étape vers une compréhension systémique de l’empreinte sociale et écologique de l’IA, et vers l’élaboration de scénarios d’atterrissage compatibles avec les limites planétaires et humaines.
Références
References
de l’IA peuvent devenir si grandes qu’il est susceptible d’impacter directement de nombreuses activités humaines, au delà des utilisations traditionnelles de l’IA.
(2019-2023) et Claudia Négri (2019-2023)
Ding (2024-2027)
Flux-Infrastructure-Besoins (FIB) — car elle est plus parlante pour refléter les matérialités des concepts en jeu.
à l’IA de 1680 TWh à 3550 TWh par an d’ici 2050.
Christophe Dabitch, Editions Sud Ouest
transportées…
remplacer le tram: les voitures, la voirie, les parkings pour les voitures, les stations-service…
place de l’infrastructure: une liberté supplémentaire de déplacement, un confort amélioré et un gain de temps.
de voitures et d’usages de celle-ci.
déplacements, ce qui va inciter les habitants à aller se loger plus loin du centre dans ces zones dont l’accès est rendu nouvellement possible grâce à la voiture entrainant une augmentation de l’usage.
dégradation du réseau au sortir de la guerre, et donc une réduction exogène de l’infrastructure.
donnée à la reconstruction, ce qui a facilité l’acceptation de la suppression du tram électrique, et son remplacement par son alternative plus moderne du bus diesel, toujours de façon exogène.
qu’à la lumière de deux effets exogènes: le délitement de l’infrastructure lié aux effets de la Seconde Guerre mondiale, et la culture automobile, érigée en symbole de progrès après la Libération et l’intervention de l’état centralisateur au travers du commissariat à la reconstruction.
d’entretien du réseau historique. Parmi eux : les contraintes esthétiques ayant conduit à l’adoption de systèmes APS peu fiables, l’effet repoussoir exercé sur les classes bourgeoises par la facilité d’accès des classes populaires au centre-ville, l’absence de lobbying en faveur de la maintenance des infrastructures existantes, ou encore le désengagement progressif de l’État [Turnheim 2023].
bien-être évalue l’expérience d’un individu en fonction des affects positifs et négatifs qu’il ressent, ainsi que de la satisfaction de ses désirs ou préférences.
sur la réalisation de soi, le sens donné à la vie, et l’actualisation du potentiel personnel, au-delà du simple plaisir ou de la satisfaction momentanée.
négative perçue, alors que la disparition d’une espèce d’amphibien lors de la construction d’une autoroute est latente.
des externalités latente: les personnes touchées souffrent du manque de perspectives dans l’avenir et sur les générations futures, sans nécessairement en percevoir les effets immédiats [Stanley et al. 2021].
2018](#ref-meadows2018limits)]. Même si les scénarios de décroissance et d’effondrement sont rarement abordés dans la recherche en informatique [Bugeau and Ligozat 2023], nous pensons qu’il est pertinent de les présenter dans notre cadre conceptuel.
informatiques et de la gestion des e-waste ont été publiée montrant le problème et les limites des solutions [Kiddee et al. 2013]
de caractéristiques, entraînement, test et inférence
et leur part dans la puissance installée, cette condition n’est pas réalisée aujourd’hui, même si de nombreux acteurs du cloud achètent les certificats ER correspondants et investissent dans les ER (e.g. https://s.nextnet.top/clean_apple).
recyclable en boucle fermée, mais seulement valorisable sous forme de granulat.
données utilisées pour entrainer le modèle et celle actuellement disponible. Dans le cas des LLM, ce phénomène peut participer à la désinformation [Fastowski and Kasneci 2024]
automatique pendant les JO de Paris 2024, dont la pérennisation au-delà du 31/03/25 est demandée par la préfecture de police https://s.42l.fr/JTRs_YJd.
échange du service GMail [Newman 2013]
de DeepSeek, mais leurs conditions de substistance soulèvent des questions éthiques [Casilli et al. 2025]
avec des périmètres différents et parfois un privilège d’accès des pouvoirs publics (PIPL).
soutenabilité de l’infrastructure ICT fait débat [Mollen et al. 2024]
et éthique du numérique*, où nous avons étudié l’impact du moteur de recommandation sur la production audiovisuelle européenne.
civilisationel, décesissant l’être humain de son libre arbitre au profit des algorithmes [Sadin 2016].
anthropomorphique, ce qui crée une confusion sans précédent quant à la confiance que le public peut lui accorder.
une IA centralisée dans les datacenters des GAFAM. Le projet CUPID25 vise à proposer une alternative et à en évaluer la soutenabilité.
et l’accélérateur d’IA Hailo-8, permettant de réduire drastiquement la consommation énergétique liée à l’inférence.
Blockchain, aspects socio-téchniques: voir thèses de Nicolas Six ↩
Confiance et IA voir thèses d’Eddy Kiomba (2022-2025) et Yuntian ↩
Dans ce document, j’emploie une terminologie légèrement différente — ↩
Deloitte prévoit une augmentation de la consommation électrique liée ↩
https://s.nextnet.top/tram “Le tramway de Bordeaux, une histoire,” ↩
le carburant des voitures, les consommables, les marchandises ↩
les nouvelles infrastructures routières construites à Bordeaux pour ↩
Les besoins sont les bénéfices individuels espérés par la mise en ↩
l’augmentation du nombre de routes disponibles augmente le nombre ↩
l’usage de la voiture individuelle permet un gain de temps dans les ↩
Dans le cas du tram de bordeaux, celui-ci a été facilité par la ↩
Pour notre exemple, le contexte d’après-guerre est la priorité ↩
L’état précédent du système (période 1900-1946) n’a pu être dépassé ↩
Plusieurs autres facteurs ont été avancés pour expliquer le manque ↩
https://ontouml.org/ ↩
Hédonique: Relatif au plaisir immédiat, l’approche hédonique du ↩
Eudémonique: L’approche eudémonique du bien-être se concentre ↩
à titre d’exemple, les bouchons sur la rocade sont une externalité ↩
le phénomène d’éco-anxiété serait la manifestation la plus directe ↩
l’approche par scénario est inspirée de [[Meadows et al. ↩
de nombreuses études portant sur le cycle de vie des appareils ↩
Cycle de vie de l’IA: collecte de données, préparation, extraction ↩
IA et ER: étant donné le caractère parfois intermittant des ER ↩
60 % du poids d’une éolienne est constitué de béton, qui n’est pas ↩
le model drift découle de la disparité grandissante entre les ↩
Citons l’autorisation temporaire de la reconnaissance faciale ↩
Citons par exemple l’utilisation des données privées par Google en ↩
Les “Data Annotators” chinois jouent un rôle crucial dans le succès ↩
l’AI act Européen est un exemple. ↩
par exemple RGPD en Europe, CPRA en Californie ou PIPL en chine, ↩
le “European Green Deal” est un exemple. ↩
Même si la pertinence des décisions du régulateur vis-à-vis de la ↩
Voir ma participation à la Chaire de Paris 1 : *Pluralisme culturel ↩
Eric Sadin va jusqu’à suggérer l’instauration d’un nouveau modèle ↩
Les récentes mises à jour de ChatGPT l’ont rendu extrêmement ↩
Les assistants domotiques comme Alexa ou Google Home sont basés sur ↩
Nous avons commencé à travailler avec la plateforme Raspberry Pi 5 ↩